DAGTrainSM).Storable.
Sequences.DataSet from a StringExtractor
using the given AlphabetContainer.
DataSet from a StringExtractor
using the given AlphabetContainer and all overlapping windows of
length subsequenceLength.
DataSet from a StringExtractor
using the given AlphabetContainer and a delimiter
delim.
DataSet from a StringExtractor
using the given AlphabetContainer, the given delimiter
delim and all overlapping windows of length
subsequenceLength.
DataSet from a given DataSet and a given
length subsequenceLength.This constructor enables you to use subsequences of the elements of a
DataSet.
DataSet from an array of Sequences and a
given annotation.This constructor is specially designed for the method
StatisticalModel.emitDataSet(int, int...)
DataSet from a Collection of Sequences and a
given annotation.
DataSet.DataSet.ElementEnumerator on the given DataSet
data.
enum defines different partition methods for a
DataSet.Sequences that occur more
than once in one or more DataSets.DataSet.WeightedDataSetFactory on the given
DataSet(s) with DataSet.WeightedDataSetFactory.SortOperation sort.
DataSet.WeightedDataSetFactory on the given
DataSet and an array of weights with
DataSet.WeightedDataSetFactory.SortOperation sort.
DataSet.WeightedDataSetFactory on the given
DataSet and an array of weights with a given
length and DataSet.WeightedDataSetFactory.SortOperation sort.
DataSet.WeightedDataSetFactory on the given array of
DataSets and an array of weights with a given
length and DataSet.WeightedDataSetFactory.SortOperation sort.
enum defines the different types of sort operations
that can be performed while creating a DataSet.WeightedDataSetFactory.RecyclableSequenceEnumerator of Sequences that enumerates all k-mers that exist in a given DataSet, optionally ignoring reverse complements.DataSet data by extracting all k-mers.
Result that contains a DataSet.DataSetResult from a DataSet with the
annotation name and comment.
Storable.
SequenceIterator from the DataSet
sample preserving as much annotation as possible.
enum defines a number of data types that can be used for
Parameters and Result
s.FileFilter that accepts Files that were modified after the date that is given in the constructor.Files that were modified after the given year, month, ...
Files that were modified after d.
It contains the class
ClassifierAssessment that
is used as a super-class of all implemented methodologies of
an assessment to assess classifiers.Classifiers that are based on SequenceScores.It includes a sub-package for discriminative objective functions, namely conditional likelihood and supervised posterior, and a separate sub-package for the parameter priors, that can be used for the supervised posterior.
DifferentiableStatisticalModels by
a unified generative-discriminative learning principle.DifferentiableStatisticalModels either
by maximum supervised posterior (MSP) or by maximum conditional likelihood (MCL).AbstractScoreBasedClassifiers that are based on
SamplingDifferentiableStatisticalModels
and that sample parameters using the Metropolis-Hastings algorithm.Classifiers that are based on TrainableStatisticalModels.The base classes to represent data are
Alphabet and AlphabetContainer for representing alphabets,
Sequence and its sub-classes to represent continuous and discrete sequences, and
DataSet to represent data sets comprising a set of sequences.DNAAlphabet for the most common case of DNA-sequences.The implementations of sequences currently include
DiscreteSequences prepared for alphabets of different sizes, and ArbitrarySequences that may
contain continuous values as well.As sub-package provides the facilities to annotate
Sequences.Sequences using a number of pre-defined annotation types, or additional
implementations of the SequenceAnnotation class.Storables to an XML-representation.Parameter-interface.Parameter values.SequenceScores, which can be used to score a Sequence, typically using some model assumptions.StatisticalModels, which can compute a proper (i.e., normalized) likelihood over the input space of sequences.StatisticalModels can be further differentiated into TrainableStatisticalModels,
which can be learned from a single input DataSet, and DifferentiableStatisticalModels,
which define a proper likelihood but can also compute gradients like DifferentiableSequenceScores.DifferentiableStatisticalModels, which can compute the gradient with
respect to their parameters for a given input Sequence.DifferentiableStatisticalModels that are directed graphical models.BayesianNetworkDiffSM.BayesianNetworkDiffSM as
a Bayesian tree using a number of measures to define a rating of structures.BayesianNetworkDiffSM as
a permuted Markov model using a number of measures to define a rating of structures.DifferentiableStatisticalModels that are homogeneous, i.e.DifferentiableSequenceScores that are mixtures of other DifferentiableSequenceScores.TrainableStatisticalModels, which can
be learned from a single DataSet.AbstractHMM.OutputStream.
ProgressUpdater and prints the
percentage of iterations that is already done on the screen.DefaultProgressUpdater.
AbstractMixtureDiffSM.isNormalized().
ParameterSet for any parameter set of
a DiscreteGraphicalTrainSM.Storable.
length.
DataSet data and
the DataSets samples.
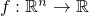 .
.HigherOrderHMM and a DifferentiableStatisticalModel by implementing some of the declared methods.Storable.
ScoreClassifier.DifferentiableSequenceScores.Storable.
Optimizer.OptimizableFunctions that are based on DifferentiableSequenceScores.Exceptions depending on wrong dimensions of vectors
for a given function.DimensionException with standard error message
("The vector has wrong dimension for this function.").
DimensionException with a more detailed error
message.
enum defines physicochemical, conformational, and letter-based dinucleotide properties of nucleotide sequences.DinucleotideProperty.MeanSmoothing that averages over windows of width width.
DinucleotideProperty.MedianSmoothing that computes the median over windows of width width.
DinucleotideProperty.Smoothing that conducts no smoothing.Strings.Storable.
InstantiableFromParameterSet
interface.
DiscreteAlphabet from a minimal and a maximal
value, i.e.
DiscreteAlphabet from a given alphabet as a
String array.
ParameterSet of a
DiscreteAlphabet.DiscreteAlphabet.
DiscreteAlphabet.DiscreteAlphabetParameterSet with empty values.
DiscreteAlphabet.DiscreteAlphabetParameterSet from an alphabet
given as a String array.
DiscreteAlphabet.DiscreteAlphabetParameterSet from an alphabet
of symbols given as a char array.
Storable
.
DiscreteAlphabet.DiscreteAlphabetMapping.
Storable.
DiscreteEmission based on the equivalent sample size.
DiscreteEmission defining the individual hyper parameters.
DiscreteEmission from its XML representation.
Storable.
DataSets for discrete inhomogeneous models by a naive implementation.Sequences of a specific
AlphabetContainer and length.DiscreteSequenceEnumerator from a given
AlphabetContainer and a length.
pos of the
Sequence.
BNDiffSMParameter, which is defined not to be free.
DoubleLists are used during the parallel computation of the gradient.
DoubleLists that are used while
computing the partial derivation.
DNAAlphabet.AlphabetContainer that can be used for DNA.ParameterSet of a DNAAlphabetContainer.DataSets of DNA Sequences.fName.
fName.
fName using the given parser.
Sequence seq fulfills all
requirements defined in the BNDiffSMParameter.context.
LogPrior that does not penalize any parameter.DifferentiableSequenceScore is a MutableMotifDiscoverer.
train-method
Comparator of double arrays.double.DoubleList with
initial length 10.
DoubleList with
initial length size.
Storable.
DoubleSymbolException is thrown if a symbol occurred more than once
in an alphabet.DoubleSymbolException that takes the symbol
that occurs more than once in the error message.
contrast and
endIdx-startIdx distributions drawn from a Dirichlet density centered around contrast, i.e.
contrast[i] each weighted by weights[i]
kls.length distributions drawn from a Dirichlet density centered around contrast, i.e.
ess (equivalent sample size)
as hyperparameters.
Storable.